
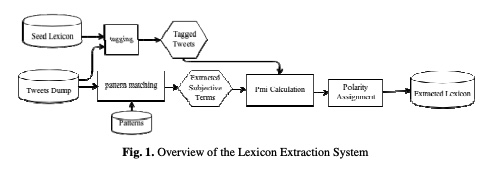
A fully automated approach for Arabic slang lexicon extraction from microblogs
With the rapid increase in the volume of Arabic opinionated posts on different social media forums, comes an increased demand for Arabic sentiment analysis tools and resources. Social media posts, especially those made by the younger generation, are usually written using colloquial Arabic and include a lot of slang, many of which evolves over time. While some work has been carried out to build modern standard Arabic sentiment lexicons, these need to be supplemented with dialectical terms and continuously updated with slang. This paper proposes a fully automated approach for building a
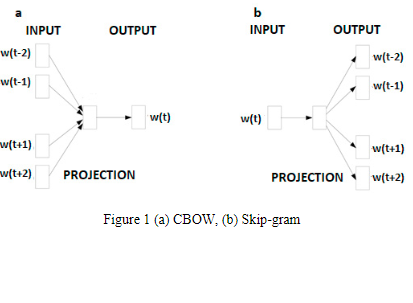
AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP
Advancements in neural networks have led to developments in fields like computer vision, speech recognition and natural language processing (NLP). One of the most influential recent developments in NLP is the use of word embeddings, where words are represented as vectors in a continuous space, capturing many syntactic and semantic relations among them. AraVec is a pre-Trained distributed word representation (word embedding) open source project which aims to provide the Arabic NLP research community with free to use and powerful word embedding models. The first version of AraVec provides six

Investigating analysis of speech content through text classification
The field of Text Mining has evolved over the past years to analyze textual resources. However, it can be used in several other applications. In this research, we are particularly interested in performing text mining techniques on audio materials after translating them into texts in order to detect the speakers' emotions. We describe our overall methodology and present our experimental results. In particular, we focus on the different features selection and classification methods used. Our results show interesting conclusions opening up new horizons in the field, and suggest an emergence of
Multimodal Video Sentiment Analysis Using Deep Learning Approaches, a Survey
Deep learning has emerged as a powerful machine learning technique to employ in multimodal sentiment analysis tasks. In the recent years, many deep learning models and various algorithms have been proposed in the field of multimodal sentiment analysis which urges the need to have survey papers that summarize the recent research trends and directions. This survey paper tackles a comprehensive overview of the latest updates in this field. We present a sophisticated categorization of thirty-five state-of-the-art models, which have recently been proposed in video sentiment analysis field, into
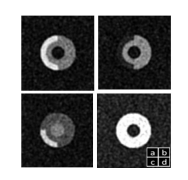
Automated cardiac-tissue identification in composite strain-encoded (C-SECN) images using fuzzy K-means and bayesian classifier
Composite Strain Encoding (C-SENC) is an MRI acquisition technique for simultaneous acquisition of cardiac tissue viability and contractility images. It combines the use of black-blood delayed-enhancement imaging to identify the infracted (dead) tissue inside the heart wall muscle and the ability to image myocardial deformation (MI) from the strain-encoding (SENC) imaging technique. In this work, we propose an automatic image processing technique to identify the different heart tissues. This provides physicians with a better clinical decision-making tool in patients with myocardial infarction
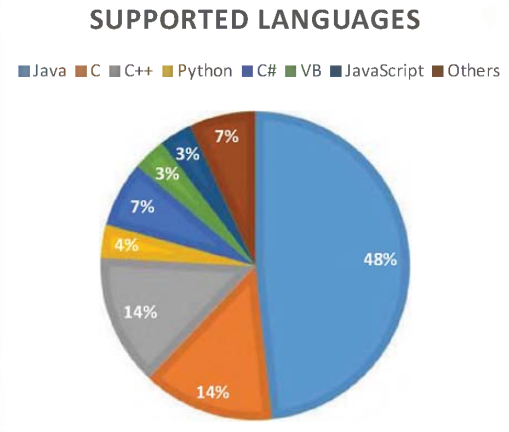
Code Smells and Detection Techniques: A Survey
Design and code smells are characteristics in the software source code that might indicate a deeper design problem. Code smells can lead to costly maintenance and quality problems, to remove these code smells, the software engineers should follow the best practices, which are the set of correct techniques which improve the software quality. Refactoring is an adequate technique to fix code smells, software refactoring modifies the internal code structure without changing its functionality and suggests the best redesign changes to be performed. Developers who apply correct refactoring sequences
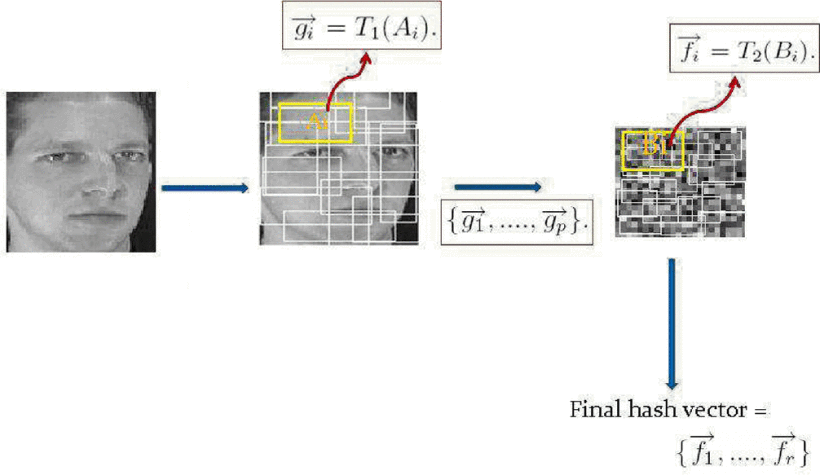
A secure face verification system based on robust hashing and cryptography
Face verification has been widely studied during the past two decades. One of the challenges is the rising concern about the security and privacy of the template database. In this paper, we propose a secure face verification system which employs a user dependent one way transformation based on a two stage hashing algorithm.We first hash the face image using a two stages robust image hashing technique, then the result hash vector is encrypted using Advanced Encryption Standard (AES). Both the hashing and the encryption/decryption keys are generated from the user claimed ID, using a modified
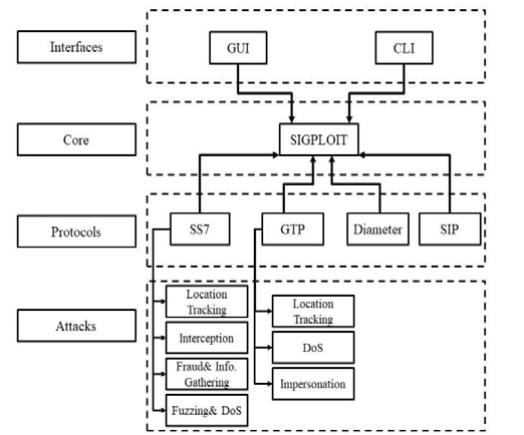
SigPloit: A New Signaling Exploitation Framework
Mobile communication networks are using signaling protocols to allow mobile users to communicate using short messages, phone calls and mobile data. Signaling protocols are also used to manage billing for operators and much more. The design flaws that signaling inherits made them vulnerable to attacks such as location tracking of subscriber, fraud, calls and SMS interception. With the high rate of these emerging attacks on telecommunication protocols there is a need to create a comprehensive penetration testing framework for signaling. In this paper, we propose a framework called Sigploit that
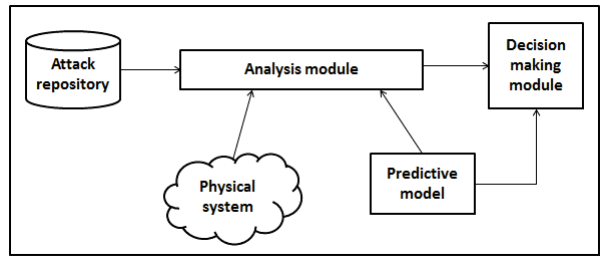
Security Perspective in RAMI 4.0
Cloud Computing, Internet of Things (IoT) are the main technologies contributing to the adoption of the fourth revolution in manufacturing, Industry 4.0 also known as smart manufacturing or digital manufacturing. Smart manufacturing facilitates and accelerates the process of manufacturing with the connection of all the systems related to the manufacturing process starting with the Enterprise Resource Planning (ERP) systems, the Industrial Control Systems (ICSs) which control the production line and the Cyber Physical Systems (CPSs). Before the emerging of web applications, cloud applications
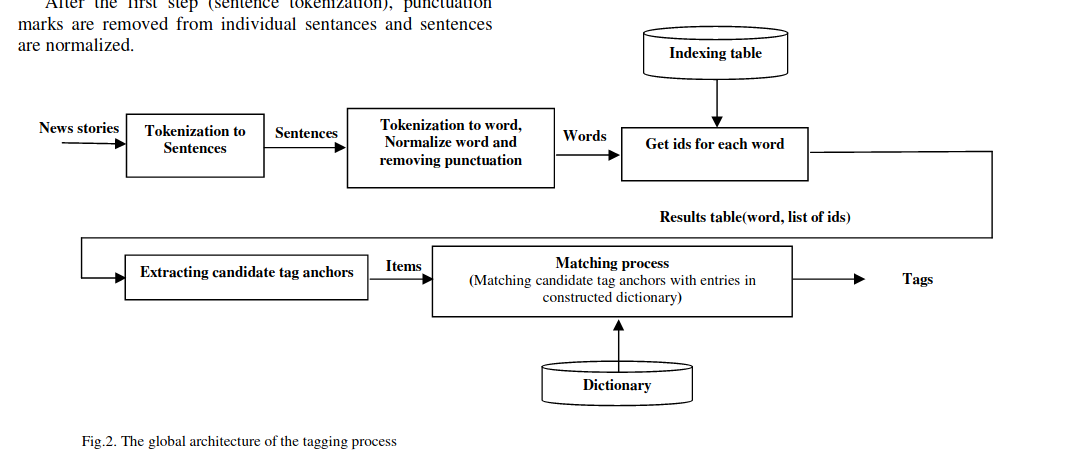
News auto-tagging using Wikipedia
This paper presents an efficient method for automatically annotating Arabic news stories with tags using Wikipedia. The idea of the system is to use Wikipedia article names, properties, and re-directs to build a pool of meaningful tags. Sophisticated and efficient matching methods are then used to detect text fragments in input news stories that correspond to entries in the constructed tag pool. Generated tags represent real life entities or concepts such as the names of popular places, known organizations, celebrities, etc. These tags can be used indirectly by a news site for indexing